Model vs Modeler: Trade-offs designing interactive text classification interfaces
Using simulations to design for interactive machine learning

This blog post summarizes a conference paper presented at IUI 2022 (pdf). If you prefer video, see my presentation at the conference.
Here’s a common situation: I’ve got a collection of text documents and an idea for a classification task. I decide I want to use machine learning to explore the feasibility of this idea. To annotate data and train a model, I’ll use interactive machine learning (IML). To do the annotation, I’ll use something like this mock IML labeling interface:

The most fundamental feature is displaying documents alongside annotation buttons, so that I can assign labels to individual documents. As I label, I also want an estimate of my model’s performance. A performance estimate helps me (a) feel like I’m making progress, (b) decide when to stop labeling, and (c) estimate how many more labels I’ll need to get. To produce a performance estimate, I’ll have to estimate my model’s performance on the labels I’ve created so far (since I started from zero labels). I’ll use leave-one-out cross-validation (CV) to compute whatever performance metrics I care about (e.g. F1 score).
I can’t display a performance estimate (or get a feeling for the feasibility of the task) until I’ve labeled documents in all of the classes. If the percentage of positive documents is low, I might have to annotate dozens of documents before I get any positive labels at all. Common practical advice is to filter your pool to identify positive documents in some subset of your data. For text data, we can add a full-text search feature to our interface so that the user can filter the unlabeled documents to find positive examples.
Finally, the most important feature of an IML interface is automatically sampling the unlabeled documents shown to the user. Rather than sampling randomly from the pool of unlabeled documents, the interface will use active learning to sample the batch of documents that will most improve the performance of the model.
Identifying trade-offs between the model and the modeler
Our mock interface is reasonable for annotating a few hundred documents and deciding if the classification task is feasible. But when I tried to design an actual IML labeling interface, I became confused. Active learning is appealing because it means I can achieve better model performance with less time spent using the interface. But in the cold-start setting, I don’t have a separate labeled validation set: does using active learning mean my model performance estimates will be biased or unreliable? I also worried about searching for data to label: a really convenient feature for exploring the dataset and labeling uncommon positive examples, but since I’m implicitly sampling from a different distribution than the full dataset I might be destroying my ability to reason about my model’s generalization performance.
The purpose of our work (presented at IUI 2022) is to show that you do need to worry about this: there is a real trade-off between boosting generalization performance and estimating that performance. You need to account for these trade-offs when designing for a specific user experience. In our work, we explicitly compared various desirable features (like search and active learning) using simulations.

Here’s the basic formulation we used to simulate the usage of an IML labeling interface: (1) The interface samples batches of 10 unlabeled documents and presents them to the user. (2) Our simulated user then provides annotations for all 10 of the documents in the batch. The simulated user provides the ground truth annotation for each document without labeling noise, an assumption that lets us compare between experiments more fairly. For our experiments, we used the Amazon Customer Reviews Dataset, and in this post we focus on classifying whether a product review is written about a book or not.

Once a batch is labeled, we use CV over all the existing labels to generate an estimate of how well our model is performing so far. The model I used is logistic regression over RoBERTa contextualized embeddings, which performs well while being fast enough to train that it can back an interactive interface. Since we’re focusing on whether the classification task is feasible, we’re just going to focus on the first 200 labels (20 batches): the “early stage” of the annotation process.
Simulating an IML labeling interface
To show how our simulations work, let’s visualize the performance estimates a user would see after they labeled each of the 20 batches.
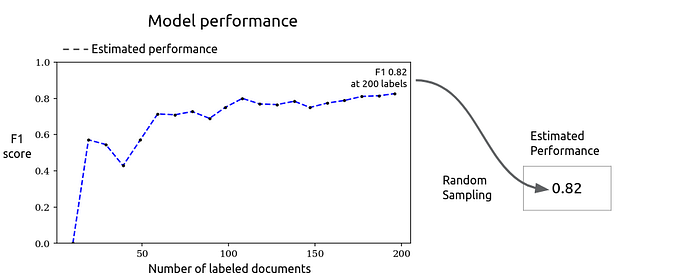
After a few fluctuations, the model reached an estimated F1 score of 0.82.
Because we’re using simulations, we can go beyond the estimated model performance and also determine how biased the performance estimate actually is by using the model to make predictions on a held-out test set, which I’ll add as a solid line.
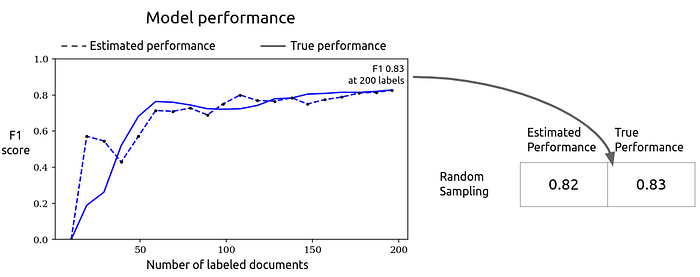
The model’s “true” generalization performance was 0.83 after 200 labels, which is close to the estimate. This example is from just one simulated run, but we can take the mean of 100 runs to show the average run’s performance. We’ll also add 95% confidence intervals for the mean:
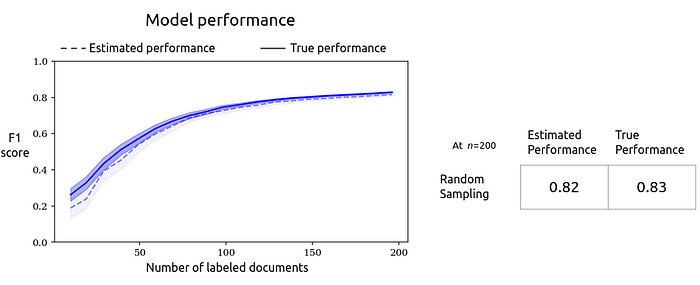
For estimated performance, despite some variance, we can see that CV provides low-bias estimates of performance. On average, these estimates are slightly pessimistic (i.e., “dashed line lower than solid line”), since in each CV fold we are holding out a single document that — if included — would improve the model’s true generalization performance.
What if we use active learning instead of random sampling to select the documents in each batch? We have to use random sampling for the first batch, but once we’ve trained a model we can use uncertainty sampling to identify the 10 documents that are closest to the model’s current decision boundary.
Uncertainty sampling is widely used, because it’s straightforward to implement and generally improves generalization performance.
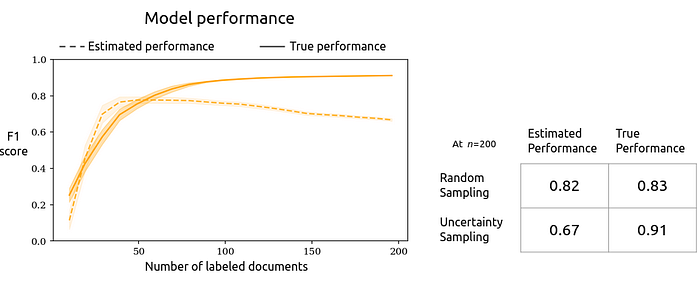
We can see the benefit of uncertainty sampling in our results: the true performance at 200 labels is almost 0.1 higher than the randomly-sampled model. But uncertainty sampling violates CV’s statistical assumptions. For the estimated performance, we see a troubling trend: as more data is labeled, the estimated performance actually decreases. If the interface reported these performance estimates to the user, they would falsely conclude their model performs more than 0.3 F1 lower than it actually does, which could be the difference between deciding to invest more annotation resources or scrapping the project as infeasible.
Even if — in some particular use case — we don’t care about accurate model performance estimates, we might still be dissatisfied with active learning methods like uncertainty sampling that require already having a trained model. For our book classification task, about 25% of documents are positive, which is only a bit imbalanced. In more extreme cases, it can be hard to find positive examples (which will lead to a worse classifier). We addressed this problem by “seeding” our classifier with positive labels by conducting full-text searches (using queries like “book” or “plot”) to filter the unlabeled pool. If we use search to filter the pool before sampling our 10 random documents, we’ll end up with a more balanced set of document labels, which will let us train a model right away and potentially improve the model overall. (We collected queries by surveying data scientists, and notably the queries people gave us were effective at filtering the pool to include a higher proportion of positive documents.)
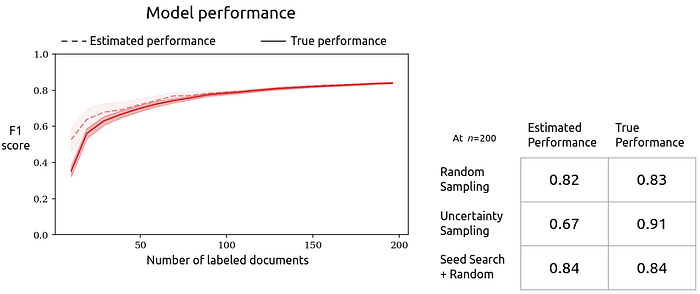
Using seed search in the first batch, we do see a modest improvement in true performance on the book task. We do still pay for this improvement with increased bias in our performance estimate. Fortunately, it’s not bad compared to uncertainty sampling: the estimate’s bias starts high, but decreases over time as long as we keep sampling randomly after our initial seed batch. Ongoing use of search beyond that first batch does substantially increase the bias of performance estimates (see the paper).
Implications for designers: what should you do about these trade-offs?
You can find more simulations in the paper, but the core thrust of our results is a trade-off between methods that will improve the model’s generalization performance and being able to give the modeler an accurate estimate of that performance. If you’re a modeler using active learning or search, we suggest a few guidelines for you in the paper. The most important implications are for the designers of IML labeling systems:
1) Don’t show the user a live estimate of model performance if it is likely to be inaccurate.
2) Discourage search and non-random sampling if model performance estimates are important to the user. I personally like the suggestion by Wall et al. (2019) to offer literal prompts to encourage or discourage particular kinds of labeling or exploration throughout the annotation process.
3) Encourage search for positive samples early in the annotation process to increase generalization performance. Not only is this unlikely to hurt true performance, but also there is qualitative evidence that people value this opportunity to explore the data and to reshape their understanding of the annotation task.
4) Encourage use of non-random sampling when true performance is the primary or only objective. Our results suggest that, in the absence of domain shift or a need to estimate model performance, it will help to use active learning methods.
Feel free to check out the paper for more simulations, including experiments with other active learning methods and combining active learning and random sampling in the same batch. If you’re interested in doing similar simulations, you can find the code on GitHub. Thanks for reading, and please let me know if our results resonate with your own experiences training interactive models or designing IML labeling systems.
I did this work while I was an intern on Vanessa Murdock’s team at Amazon. Huge thanks to Max Harper and CJ Lee for acting as my direct mentors. If you want to know more about IML labeling interfaces and best practices in annotation, I recommend Robert (Munro) Monarch’s book “Human-in-the-Loop Machine Learning”.
